# Import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns # for visualiation
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler # scaling data
from sklearn.neighbors import KNeighborsRegressor # regressor
from sklearn.model_selection import GridSearchCV # for grid search
from sklearn.pipeline import make_pipeline # for making pipelines
from sklearn.preprocessing import LabelEncoder
# Assess the accuracy of predictions
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from IPython.display import HTML
# Import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns # for visualiation
import scipy
from datetime import datetime
from sklearn.svm import SVC
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_selection import RFECV
from sklearn.datasets import make_classification
import sklearn as sk
from sklearn import ensemble
from sklearn import metrics
from sklearn.neural_network import MLPRegressor
import matplotlib.patches as mpatches
import warnings
warnings.filterwarnings('ignore')
pd.options.display.max_columns = None
%matplotlib inline
import statsmodels.formula.api as smf # linear modeling
import warnings
warnings.filterwarnings('ignore')
shooting_and_sales_per_pop = pd.read_csv('./data/shootings_and_sales_per_pop.csv')
from IPython.display import HTML
HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide();
} else {
$('div.input').show();
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
<form action="javascript:code_toggle()"><input type="submit" value="Show raw code."></form>''')
Analysis of U.S. Gun Sales¶
Within the last decade, the topic of gun violence and gun control has become a serious issue with opinions becoming very polar and political on what solution is the safest and most practicle for a modern America. Many people believe that the United States is in an arms race against itself and the need for citizen to carry firearms is obsolete. Others believe it is natural to want to protect yourself and your home with a firearm.
With the wide spectrum of opinion that has grown in America, we wanted to pose a question near the root of the problem: Can gun sales be predicted by mass shootings?
Data Sources¶
We gathered data from a wide variety of sources in our research. The first source we used was from the Gun Violence Archive which provided key data on our primary variable of interest: gun violence. The GVA was founded in 2013 to provide public data on mass shootings. This data provided a baseline for the timeseries of our models.
The second source we used was the National Criminal Background Check System. From this source we extrapelated the total number of gun sales, which is our dependent variable.
Finally, we used population data from the U.S. Census Bureau to normalize different features on the state level. Unfortunately, this data is yearly rather than monthly so it is not as accurate. However, we felt that this still accurately represented the population so we just used the yearly counts.
Data Cleaning and Feature Creation¶
The data preperation was a three part process. The first step in preparing the data was to concatonate all of the mass shooting data by year into one dataframe. This was convienent since all of our data came from the same source. The second step focused on gun sales in the US. This data was also already packaged nicely, the only work needed was to split up the month and year to force them into integers for merging and totaling the counts for the US as a whole. Then, state population was added to the sales dataframe to later create features relative to population.
The final step in creating the dataframe was to merge the shooting data with the gun sale data. Once that was complete, we were ready for feature selection. The first feature we decided to create was the number of people affected, which is simply number of people injured and number of people killed. Then to quantify large incidents we created a boolean that measured if over 10 people were affected in the incident. The next two features we added the average number of of deaths and injuries based on the number of incidents in each month. Finally, we normalized the values based on population of the state in which they occured.
- state, year, month: These are our indexing columns, data is sorted by the month and year for each state.
- population: The total yearly population of the state applied over all the months of the year.
- handgun: The number of background checks conducted for handguns.
- long_gun: The number of background checks conducted for long guns.
- multiple: The number of background checks conducted for multiple guns.
- other: The number of background checks conducted for other guns.
- total: The total number of background checks conducted in a particular state, year and month.
- killed: The number of people killed each month in mass shooting incidents in each state.
- killed_max: The highest amount of people kill in a single incident in a month.
- injured: The number of people killed each month in mass shooting incidents in each state.
- incidents: The number of mass shooting incidents in a month in a state.
- injured_max: The highest amount of people injured in a single incident in a month.
- affected_max: The highest amount of people affected in a single incident in a month.
- affected_over_10: The number of incidents in a month that affected more than 10 people.
- killed_ave: The average number of people killed per incident in each month.
- injured_ave: The average number of people injured per incident in each month.
- handgun_pop: Handgun count normalized per capita for each state in a given year.
- long_gun_pop: Long gun count normalized per capita for each state in a given year.
- multiple_pop: Mulitple gun count normalized per capita for each state in a given year.
- other_pop: Other gun count normalized per capita for each state in a given year..
- permit_pop: Number of permits rechecked normalized per capita for each state in a given year.
- totals_pop: Total number of permits normalized per capita for each state in a given year.
- killed_pop: Total number of people killed normalized per capita for each state in a given year.
- injured_pop: Total number of people injured normalized per capita for each state in a given year.
- incidents_pop: Total number of mass shooting incidents normalized per capita for each
Exploration of Data¶
Our final dataframe was a 3120 rows by 30 columns dataframe which contained gun sale, population, and mass shooting information for each state monthly. To better understand this large dataset we looked for visual relationships between our potential predictor variables and gun sales. The following is a set of insights we gained from our research.
Seasonality within both gun sales and mass shootings:¶
# Import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns # for visualiation
# creating Dataframes
gunsale_population_by_shooting = pd.read_csv('./data/shootings_and_sales_per_pop.csv')
united_states_totals = gunsale_population_by_shooting[gunsale_population_by_shooting.state == "United States"]
# First graphs size, rows, title and color set.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15,6))
fig.suptitle('Seasonality of background checks and mass shootings from 2013 - 2017')
palette = sns.color_palette("bright", 5)
# Plotting each
sns.lineplot(x="month", y="totals",
hue="year", palette = palette,
data=united_states_totals, ax=ax1)
ax1.set(xlabel='Month', ylabel='Total Firearm Background Checks')
sns.lineplot(x="month", y="incidents",
hue="year", palette = palette,
data=united_states_totals, ax=ax2)
ax2.set(xlabel='Month', ylabel='Nunber of Mass shooting incidents')
plt.show()

The seasons of each of these are almost opposite to each other. Gun sales peak towards December while mass shooting incidents increase towards the end of the summer. One important characteristic to notice is that specific events can be seen on the background checks graph. For example June of 2016 is an outlier which is when the Orlando Massacre happened.
How do state's number of mass shootings and the number of background checks relate.¶
# Remove the country totals
states_only = gunsale_population_by_shooting[gunsale_population_by_shooting.state != "United States"]
# Aggregates for different years.
states_2013_totals = states_only[states_only["year"] == 2013].groupby(["state","year"]).sum()
states_2017_totals = states_only[states_only["year"] == 2017].groupby(["state","year"]).sum()
# First graphs size, rows, title and color set.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15,6))
fig.suptitle('Number of Mass Shooting incidents VS Total Firearm Background Checks by State 2013 & 2017')
palette = sns.color_palette("bright", 5)
# Plotting
sns.regplot(states_2013_totals["totals"],
states_2013_totals["incidents"], ax = ax1)
ax1.set(xlabel='Total Firearm Background Checks', ylabel='Number of Mass Shooting Incidents')
# Adds labels to rows with state name that I preselected.
for line in range(0,states_2013_totals.shape[0]):
if states_2013_totals.reset_index().state[line] in ["California", "Texas", "Illinois", "Kentucky"]:
ax1.text(states_2013_totals.totals[line]+0.2, states_2013_totals.incidents[line],
states_2013_totals.reset_index().state[line], horizontalalignment='left', size='medium',
color='black', weight='semibold')
sns.regplot(states_2017_totals["totals"],
states_2017_totals["incidents"], ax = ax2)
ax2.set(xlabel='Total Firearm Background Checks', ylabel='Number of Mass Shooting Incidents')
# Adds labels to rows with state name that I preselected.
for line in range(0,states_2017_totals.shape[0]):
if states_2017_totals.reset_index().state[line] in ["California", "Texas", "Illinois", "Kentucky", "Florida", "Ohio"]:
ax2.text(states_2017_totals.totals[line]+0.2, states_2017_totals.incidents[line],
states_2017_totals.reset_index().state[line], horizontalalignment='left',
size='medium', color='black', weight='semibold')
plt.show()

While it may look like there is some sort of correlation from this regression plot, there are luckily a lot of states which don't have mass shootings which skews this graph. It seems the state itself has a large influence on the number of mass shootings such as Illinois and California.
What the background checks totals is made up by:¶
# Used for the time series.
dates = pd.DataFrame({"month": united_states_totals.month,
"year": united_states_totals.year,
"day": 1
})
# Created a seperate data frame for the stacked plot
just_gun_sales = pd.DataFrame({"date": pd.to_datetime(dates),
"long gun checks": united_states_totals.long_gun,
"handgun checks": united_states_totals.handgun,
"multi-gun checks": united_states_totals.multiple,
"permit checks": united_states_totals.permit,
"other": united_states_totals.other
})
stacked_check_plot = just_gun_sales.plot.area(x="date", title="Monthly Background Checks")
stacked_check_plot.set(xlabel="Date", ylabel="Number of Background checks in Month")
stacked_check_plot

Multi-gun firearm background checks are pretty rare in comparison to the other categories which helps our model be more accurate as we are trying to estimate the number of guns sold using the checks. Here you can again see a seasonality of the background checks as well as spikes from certain events like the 2016 Orlando massacre.
How does the population of a state influence the number of background checks:¶
sns.set(style="ticks")
#first_month = states_only[(states_only.year == 2013) & (states_only.month == 1)]
last_month = states_only[(states_only.year == 2017) & (states_only.month == 12)]
pop_totals_graph = sns.jointplot(last_month.population, last_month.totals, kind="hex", height=10, color="#4CB391")
pop_totals_graph.set_axis_labels('State Population in Millions', 'Number of Background checks in Month', fontsize=16).fig.suptitle('December 2017')
pop_totals_graph

We wanted to understand if it was reasonable to normalize the number of background checks by the states population. The distribution of both appear to be right skewed, but from our graph the relationship between the two seem pretty clear. There are outliers such as Kentucky, but overall we assumed it was a smart idea to normalize for the population of the state.
Feature Selection¶
overall = pd.read_csv('./data/shootings_and_sales_per_pop.csv')
us_df = overall[overall.state=='United States']
df = overall[overall.state!='United States']
training = ['year','population','month',
'killed','state',
'killed_max','injured','incidents',
'injured_max','affected_max','affected_over_10',
'killed_ave','injured_ave',
'killed_pop','injured_pop','incidents_pop']
testing = ['totals_pop']
le = sk.preprocessing.LabelEncoder()
le.fit(df.state)
df.state = le.transform(df.state)
us_df.state = 0
df.totals_pop = df.totals_pop.apply(lambda x:int(x))
us_df.totals_pop = us_df.totals_pop.apply(lambda x:int(x))
train = sk.preprocessing.scale(df[training])
us_train = sk.preprocessing.scale(us_df[training])
# Build a classification task using 3 informative features
X_train, X_test, y_train, y_test = sk.model_selection.train_test_split(train,df[testing],train_size=.8,random_state=10)
# Create the RFE object and compute a cross-validated score.
svr = sk.svm.SVR(kernel='linear')
# The "accuracy" scoring is proportional to the number of correct
# classifications
rfecv = RFECV(estimator=svr, step=1, cv=StratifiedKFold(10),
scoring='neg_mean_squared_error')
y_train = y_train.values.ravel()
y_test = y_test.values.ravel()
rfecv.fit(X_train, y_train)
print("Optimal number of features : %d" % rfecv.n_features_)
# Plot number of features VS. cross-validation scores
plt.figure()
plt.title('Recursive Feature Elimination with Cross Validation')
plt.xlabel("Number of features selected")
plt.ylabel("Cross validation(5) score (neg_mean_squared_error)")
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show()

Here are our final features
ranked = rfecv.ranking_.copy()
ranked[ranked==1]=True
ranked[ranked!=True]=False
features = []
for t,r in zip(training,ranked):
if(r):
features.append(t)
features
Models¶
Statistical Model¶
As for the statistical modeling, we first wanted to see which features have correlations with each other and most importantitly we wanted to identify which feature specifically correlates with the number of gun sales or total gun sales (_totals_pop_) for each state, year and month.
shooting_and_sales_per_pop = shooting_and_sales_per_pop[shooting_and_sales_per_pop.state != 'United States']
# Select optimal features for your model
corr = shooting_and_sales_per_pop.corr()
# Generate a mask for the upper triangle
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
f, ax = plt.subplots(figsize=(11,9))
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})

Total Firearms background checks by population each Month in each state¶
Next we chose to use linear regression to do our statistical analysis and predict gun sales for each state given features like or a combination of features such as:
formula_1 =
totals_pop ~ year + population + month + state + injured + incidents + injured_ave + killed_pop + injured_pop + incidents_pop.
The reason we chose linear regression is because our data contains continuous numerical values that is easy to test against a independent variable like time (year, month).
full_model = smf.ols(formula='totals_pop ~ year + population + month + state + injured + incidents + injured_ave + killed_pop + injured_pop + incidents_pop', data=shooting_and_sales_per_pop).fit()
full_model.summary()
shooting_and_sales_per_pop['mult_pred']=full_model.predict()
shooting_and_sales_per_pop.plot('totals_pop', 'mult_pred', kind='scatter')
plt.plot(shooting_and_sales_per_pop.totals_pop, shooting_and_sales_per_pop.totals_pop, color='red')
plt.show()

full_model__2 = smf.ols(formula='totals_pop ~ year + population + month + state', data=shooting_and_sales_per_pop).fit()
full_model.summary()
formula_2 =
totals_pop ~ year + population + month + state.
shooting_and_sales_per_pop['mult_pred_2']=full_model.predict()
shooting_and_sales_per_pop.plot('totals_pop', 'mult_pred_2', kind='scatter')
plt.plot(shooting_and_sales_per_pop.totals_pop, shooting_and_sales_per_pop.totals_pop, color='red')
plt.show()

# First graphs size, rows, title and color set.
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(17,6))
fig.suptitle('A combination of factors that contributed to number of background checks & mass shootings from 2013 - 2017')
palette = sns.color_palette("bright", 5)
# Plotting each
sns.lineplot(x="month", y="mult_pred",
hue="year", palette = palette,
data=shooting_and_sales_per_pop, ax=ax1)
ax1.set(xlabel='Month', ylabel='Total Firearm Background Checks Predicted')
sns.lineplot(x="month", y="incidents_pop",
hue="year", palette = palette,
data=shooting_and_sales_per_pop, ax=ax2)
ax2.set(xlabel='Month', ylabel='Number of Mass shooting incidents')
sns.lineplot(x="month", y="killed_pop",
hue="year", palette = palette,
data=shooting_and_sales_per_pop, ax=ax3)
ax3.set(xlabel='Month', ylabel='Number of Mass shooting killed')
plt.show()

Machine Learning Models¶
train = sk.preprocessing.scale(df[features])
us_train = sk.preprocessing.scale(us_df[features])
rf = ensemble.RandomForestRegressor()
gb = ensemble.GradientBoostingRegressor()
svr = sk.svm.SVR()
knn = sk.neighbors.KNeighborsRegressor()
mlp = sk.neural_network.MLPRegressor(max_iter=2000,solver='lbfgs')
train = sk.preprocessing.scale(df[features])
X_train, X_test, y_train, y_test = sk.model_selection.train_test_split(train,df[testing],train_size=.8,random_state=10)
y_train = y_train.values.ravel()
y_test = y_test.values.ravel()
modelnames = ['random_forest','gradient_booster','support_vector_regression','knn','multi_layer_perceptron']
df_results = pd.DataFrame(data = {'model':modelnames,'mse':0,'mse_err':0})
models =[rf,gb,svr,knn,mlp]
i = 0
num_iters = 10
for model in models:
mse = []
for k in range(num_iters):
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
mse.append(metrics.mean_squared_error(y_test,y_pred))
for mname,mdata in zip(['mse'],[mse]):
err_name = "{}_err".format(mname)
ave = np.mean(mdata)
df_results.loc[i,mname] = ave
df_results.loc[i,err_name] = np.std(mdata) / np.sqrt(len(mdata))
i+=1
#df_results contains the models and their mean squared error and error of that values.
colors = ['#FCCE00','#0375B4','#007849','#262228','#FF7F00']
colors = ['#0E0B16','#A239CA','#4717F6','#E7DFDD','#FF7F00']
colors = ['#008DAB','#FCE700','#E81D64','#4A4A4A','#FF7F00']
plt.rcParams["figure.figsize"] = (20,15)
bigfont = 20
smallfont = 14
model_names = ['random_forest','gradient_booster','support_vector_regression','knn','multilayer_perceptron']
score_names = ['mse']
patches = []
for model_name,color in zip(model_names,colors):
patches.append(mpatches.Patch(color=color, label=model_name))
plt.bar(modelnames,df_results.loc[:,'mse'],yerr=df_results.loc[:,'mse_err'],color=colors)
#plt.xticks(np.arange(4),model_names,rotation=90,fontsize=smallfont)
plt.title('Initial Model Comparison',fontsize=bigfont,position=(0.5,1.05))
plt.ylabel('MSE')
plt.xlabel('Model')
plt.legend(handles=patches,fontsize=bigfont)
#plt.savefig('initial_model_compare.png',dpi=500,format='png')

df_results
Model of Choice¶
Based on the above initial model comparison, we decided to go forward with the random forest regressor for hyper tuning. Full code and grid search process for tuning are in elias_feature.ipynb.
A quick overview of the Random Forest Regressor is that it's an ensemble of decision trees, which proceed to vote for the resultant value from the parameters given, the decision trees are each given a different sample of the features in order to prevent overtraining and allow for different variables importance to be increased depending on how essential they are to predicting the correct result.
Interestingly, the tuned parameters for minimum samples leafs and minimum samples split are close to the default values, This makes sense given that our data isn't nearly extensive enough to justify large minimum sample leafs and splits for each decision tree. Max depth and n_estimators also reflect the small dataset, with limited depth preventing over training, and a low amount of estimators being needed to come to a conclusive decision.
rf = ensemble.RandomForestRegressor(random_state=10,
criterion='mse',
max_depth=12,
max_features=8,
min_samples_leaf=1,
min_samples_split=2,
n_estimators=10)
rf.fit(X_train,y_train)
y_pred = rf.predict(X_test)
We did an 80-20 split of training to testing data, because our quanitity of data is low, so we wanted to have more data for training.
Training our Random Forest Regressor on this training data, and then predicting based on test data provides the following graph. The x-axis is a random assortment of months, but we can see that the mse is about 20% better after tuning than the default model.
X_train, X_test, y_train, y_test = sk.model_selection.train_test_split(train,df[testing],train_size=.8,random_state=10)
plt.rcParams["figure.figsize"] = (20,15)
ax = y_test.reset_index(drop=True).plot()
pd.DataFrame(y_pred).plot(ax=ax)
plt.title('Guns sold actual vs rf predictions')
plt.ylabel('Guns Sold per 100,000')
plt.xlabel('random months from test data')
plt.legend(['actual guns sold','rf predictions guns sold'])
plt.show()

mse = metrics.mean_squared_error(y_test,y_pred)
print('The MSE of this graph is {}'.format(mse))
In order to look at how the model did across all data, we then predicted for every row of data we had, in which the below graph represents each state by month. The mse decreases, but thats expected as we run our model on data it's been trained on.
y_pred = rf.predict(train)
plt.rcParams["figure.figsize"] = (20,15)
ax = df[testing].reset_index(drop=True).plot()
pd.DataFrame(y_pred).plot(ax=ax)
plt.title('Guns sold actual vs rf predictions')
plt.ylabel('Guns Sold per 100,000')
plt.xlabel('state per month from 2013-2017')
plt.legend(['actual guns sold','rf predictions guns sold'])
plt.show()

mse = metrics.mean_squared_error(df[testing].reset_index(drop=True),y_pred)
print('The MSE of this graph is {}'.format(mse))
Having looked at the results at a state level, we then zoomed out to a national level to see how well our model predicts gun sales, and to compare seasonality importance with just shooting data importance.
Below we use a random forest regressor trained on national data to predict guns sold using the same feature set that we selected earlier.
us_rf = ensemble.RandomForestRegressor(random_state=10,
criterion='mse',
max_depth=12,
max_features=8,
min_samples_leaf=1,
min_samples_split=2,
n_estimators=10)
us_X_train, us_X_test, us_y_train, us_y_test = sk.model_selection.train_test_split(us_train,us_df[testing],train_size=.8,random_state=10)
us_rf.fit(us_X_train,us_y_train)
y_pred_us = us_rf.predict(us_X_test)
plt.rcParams["figure.figsize"] = (20,15)
ax = us_y_test.reset_index(drop=True).plot()
pd.DataFrame(y_pred_us).plot(ax=ax)
# ax.xticks=
plt.title('National: Guns sold actual vs rf predictions')
plt.ylabel('Guns Sold per 100,000')
plt.xlabel('Monthly from 2013-2017')
plt.legend(['actual guns sold','rf predictions guns sold'])
plt.show()

mse = metrics.mean_squared_error(us_y_test.reset_index(drop=True),y_pred_us)
print('The MSE of this graph is {}'.format(mse))
Below we predict gun sales just using shooting incident data from the selected feature list, while removing year and month to remove the aspect of seasonality from our model
non_seasonal = ['population','state','injured','incidents','injured_ave','killed_pop','injured_pop','incidents_pop']
non_seasonal_train = sk.preprocessing.scale(df[non_seasonal])
non_seasonal_us_train = sk.preprocessing.scale(us_df[non_seasonal])
non_seasonal_rf = ensemble.RandomForestRegressor(random_state=10,
criterion='mse',
max_depth=12,
max_features=8,
min_samples_leaf=1,
min_samples_split=2,
n_estimators=10)
non_s_us_X_train, non_s_us_X_test, non_s_us_y_train, non_s_us_y_test = sk.model_selection.train_test_split(non_seasonal_us_train,us_df[testing],train_size=.8,random_state=10)
non_seasonal_rf.fit(non_s_us_X_train,non_s_us_y_train)
non_s_y_pred = non_seasonal_rf.predict(non_s_us_X_test)
plt.rcParams["figure.figsize"] = (20,15)
ax = non_s_us_y_test.reset_index(drop=True).plot()
pd.DataFrame(non_s_y_pred).plot(ax=ax)
plt.title('National: Guns sold actual vs rf shootings based predictions')
plt.ylabel('Guns Sold per 100,000')
plt.xlabel('Monthly from 2013-2017')
plt.legend(['actual guns sold','shooting only rf predictions guns sold'])
plt.show()

mse = metrics.mean_squared_error(non_s_us_y_test.reset_index(drop=True),non_s_y_pred)
print('The MSE of this graph is {}'.format(mse))
Below we predict gun sales just using seasonality data, year and month, from the selected feature list, while removing all shooting data from the model.
seasonal = ['year','month','population','state']
seasonal_train = sk.preprocessing.scale(df[seasonal])
seasonal_us_train = sk.preprocessing.scale(us_df[seasonal])
seasonal_rf = ensemble.RandomForestRegressor(random_state=10,
criterion='mse',
max_depth=12,
max_features=4,
min_samples_leaf=1,
min_samples_split=
2,
n_estimators=10)
s_us_X_train, s_us_X_test, s_us_y_train, s_us_y_test = sk.model_selection.train_test_split(seasonal_us_train,us_df[testing],train_size=.8,random_state=10)
seasonal_rf.fit(s_us_X_train,s_us_y_train)
s_y_pred = seasonal_rf.predict(s_us_X_test)
plt.rcParams["figure.figsize"] = (20,15)
ax = s_us_y_test.reset_index(drop=True).plot()
pd.DataFrame(s_y_pred).plot(ax=ax)
plt.title('National: Guns sold actual vs rf seasonal based predictions')
plt.xticks=s_us_y_test.index
plt.ylabel('Guns Sold per 100,000')
plt.xlabel('Monthly from 2013-2017')
plt.legend(['actual guns sold','rf predictions guns sold'])
plt.show()

mse = metrics.mean_squared_error(s_us_y_test.reset_index(drop=True),s_y_pred)
print('The MSE of this graph is {}'.format(mse))
Below we present all three models for predicting shootings on a national level, despite there being some differences in MSE between models, we can see that they're all fairly close in predictions.
plt.rcParams["figure.figsize"] = (20,15)
ax = us_y_test.reset_index(drop=True).plot()
pd.DataFrame(y_pred_us).plot(ax=ax)
pd.DataFrame(s_y_pred).plot(ax=ax)
pd.DataFrame(non_s_y_pred).plot(ax=ax)
plt.title('National: Guns sold based on month')
plt.ylabel('Guns Sold per 100,000')
plt.xlabel('Monthly from 2013-2017')
plt.legend(['actual guns sold','combination rf predictions guns sold','season only rf predictions guns sold','shooting only rf predictions guns sold'])
plt.show()

# saves state prediction csvs
result_states = pd.DataFrame(columns=['prediction','actual','state','month'])
for st in range(51):
state_name = le.inverse_transform([st])
temp = df[df.state == st]
state_X_train, state_X_test, state_y_train, state_y_test = sk.model_selection.train_test_split(temp[features],temp[testing],train_size=.8,random_state=10)
state_X_training = sk.preprocessing.scale(state_X_train)
state_X_testing = sk.preprocessing.scale(state_X_test)
state_y_pred = rf.predict(state_X_testing)
temp_save = pd.DataFrame(state_y_pred).join(state_y_test.reset_index(drop=True))
temp_save['state']=state_name[0]
months = state_X_train.month.reset_index(drop=True)
years = state_X_train.year.reset_index(drop=True)
temp_save['month'] = months + (years-2013)*12
temp_save.columns = ['prediction','actual','state','month']
result_states = result_states.append(temp_save,ignore_index=True)
result_states.to_csv('./data/state_predictions.csv')
HTML('''<div class='tableauPlaceholder' id='viz1544066036206' style='position: relative'><noscript><a href='#'><img alt=' ' src='https://public.tableau.com/static/images/Ac/Actual_vs_prediction_comparison/Sheet1/1_rss.png' style='border: none' /></a></noscript><object class='tableauViz' style='display:none;'><param name='host_url' value='https%3A%2F%2Fpublic.tableau.com%2F' /> <param name='embed_code_version' value='3' /> <param name='site_root' value='' /><param name='name' value='Actual_vs_prediction_comparison/Sheet1' /><param name='tabs' value='no' /><param name='toolbar' value='yes' /><param name='static_image' value='https://public.tableau.com/static/images/Ac/Actual_vs_prediction_comparison/Sheet1/1.png' /> <param name='animate_transition' value='yes' /><param name='display_static_image' value='yes' /><param name='display_spinner' value='yes' /><param name='display_overlay' value='yes' /><param name='display_count' value='yes' /><param name='filter' value='publish=yes' /></object></div> <script type='text/javascript'> var divElement = document.getElementById('viz1544066036206'); var vizElement = divElement.getElementsByTagName('object')[0]; vizElement.style.width='100%';vizElement.style.height=(divElement.offsetWidth*0.75)+'px'; var scriptElement = document.createElement('script'); scriptElement.src = 'https://public.tableau.com/javascripts/api/viz_v1.js';vizElement.parentNode.insertBefore(scriptElement, vizElement);</script>''')
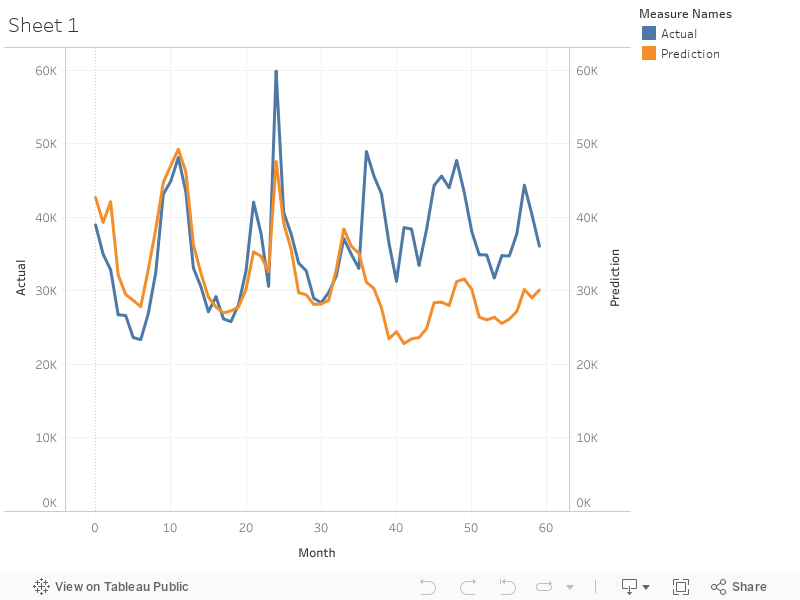
Interpretation and Analysis¶
Through modeling and trying to predict gun sales (represented by the number of firearm background checks) we evaluated the importance of mass shootings. After finding our most accurate model, then tuning it, we compared the model's predictions to the actual number of gun sales. We then removed the mass shooting data from our model and again tested it. We found that with the mass shooting data our model had a mean squared error of 21006~, while our model without the mass shooting data had a mean squared error of 11378~. We also ran a model without date related information to remove seasonality and found a mean squared error of 24961~. This shows that seasonality is the best predictor of gun sales, shooting datas mse seems to be just double, but looking at the trends we can see that the trend line just seems to average, with a few accurate predictions. A big problem is that our train and test data is limited to 59 months, so we don't have enough data points to know for certain if this is coincidental or an actual predictor.